Is your AI agent just a glorified parrot, or is it a true student of the digital world?
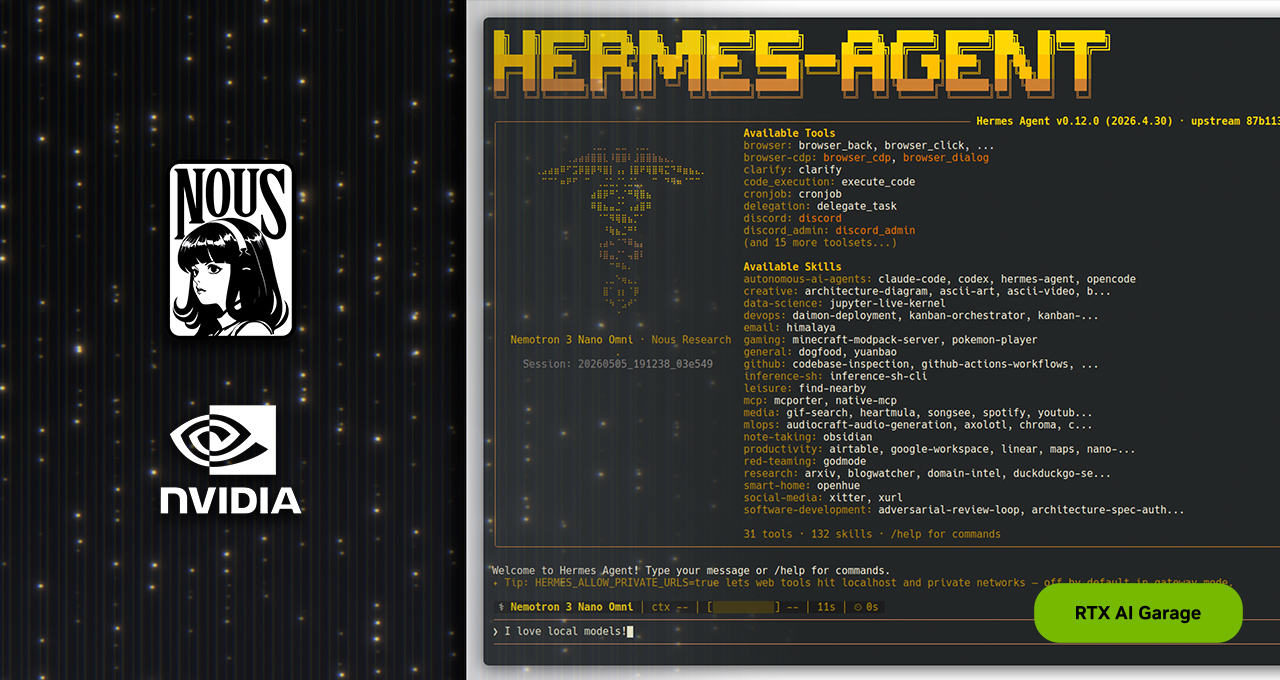
We’ve seen agentic AI burgeon, a vibrant, almost chaotic, blossoming in the open-source garden. Following the splash made by OpenClaw, the newest star to emerge is Hermes Agent. It’s not just climbing the GitHub charts – it’s crushing them, raking in over 140,000 stars in less than three months and, as of a week ago, boasting the title of the world’s most utilized agent on OpenRouter. That’s a rapid ascent, and it begs the question: what’s really under the hood?
Developed by Nous Research, Hermes touts reliability and, more importantly, self-improvement. These aren’t just buzzwords; for AI agents, they’ve historically been as elusive as a stable crypto market. The architecture is designed to be provider- and model-agnostic, which is a fancy way of saying it’s flexible. But the real kicker? It’s optimized for always-on, local execution. This is where NVIDIA’s hardware – specifically their RTX PCs, PRO workstations, and the DGX Spark platform – enters the picture as the intended high-octane fuel for this self-learning engine.
And to power these local agents, we’re seeing the rise of models like Alibaba’s Qwen 3.6. These aren’t your grandpa’s LLMs. The Qwen 3.6 27B and 35B parameter models are outgunning their predecessors that were ten times their size. Imagine the intelligence of a massive data center model shrunk down to fit on your desktop, accelerated by NVIDIA’s silicon.
The ‘Self-Evolving’ Promise: More Than Just Hype?
Hermes isn’t just another wrapper around an LLM. It integrates with your messaging apps, dips into local files, and, yes, it’s designed to run 24/7. But its claimed standout features are what really catch the eye.
First, there’s Self-Evolving Skills. The idea is that Hermes actually writes and refines its own tools, its own ‘skills.’ When it tackles a tough problem or gets a bit of direction, it’s supposed to save that learning, turning it into a reusable skill. This is the theoretical core of genuine adaptation – moving beyond pre-programmed responses to a dynamic, evolving capability.
Then you have Contained Sub-Agents. Think of these as specialized mini-workers. Hermes assigns them to specific sub-tasks, giving them just enough context and tools to do their job and then sending them packing. This isolation, according to Nous Research, keeps things clean, prevents the main agent from getting bogged down, and crucially, allows it to run with smaller context windows – a big win for those local, less VRAM-hungry models.
And what about Reliability by design? This is where the rubber meets the road for many developers. Nous Research claims they’ve meticulously curated and stress-tested every bit of the Hermes toolkit. The implication? Less fiddling, more functioning, even with models that are pushing the 30-billion-parameter mark. This is a bold claim in a space often defined by constant debugging.
Finally, Same model, better results. This one’s a direct shot at competing frameworks. Developer comparisons, they say, consistently show Hermes outperforming when using the exact same underlying LLM. The differentiator, they argue, is Hermes itself – an ‘active orchestration layer’ that enables persistent, on-device agents, not just single-shot task executions.
Why Your Graphics Card Matters More Than Ever
All this talk of local execution and self-improvement hinges on one thing: raw compute power. The quality of your experience with Hermes, and by extension, any local AI agent, is directly tied to the hardware it’s running on. NVIDIA’s RTX GPUs, purpose-built for AI workloads, become the bottleneck – or the accelerator – for these ambitious agents.
And those Qwen 3.6 models? They’re designed to bring data center-level intelligence down to earth. The 35B parameter model sips around 20GB of memory while supposedly matching models that guzzle 70GB+. The 27B variant? It’s a compact powerhouse, offering accuracy comparable to 400B parameter behemoths but at a fraction of the size. High-end RTX GPUs provide the horsepower these lean models need to operate with speed.
DGX Spark: The Always-On AI Workstation?
Agents like Hermes are envisioned as perpetually active. They’re meant to be there, waiting, responding, planning, executing, and, of course, learning. For this kind of 24/7 operation, NVIDIA’s DGX Spark enters the arena. It’s pitched as a dedicated, sustained-use machine for agentic workflows. With 128GB of unified memory and a claimed petaflop of AI performance, it’s designed to keep even those hefty MoE models humming all day. The Qwen 3.6 35B, being more efficient, should run even faster on this platform, freeing up capacity for more concurrent tasks.
NVIDIA is even offering a ‘DGX Spark playbook’ and a series of ‘Build It Yourself’ sessions. It’s clear they’re not just selling hardware; they’re trying to cultivate an ecosystem around these next-generation AI agents.
Getting Your Hands On It
So, how do you actually get Hermes running locally with this NVIDIA-enhanced setup? The process starts, as so many things do, with the Hermes GitHub repository. You’ll pair it with a local model and a runtime. Running Hermes alongside Qwen 3.6 is facilitated through popular tools like llama.cpp, LM Studio, or Ollama. For the absolute simplest entry point, Hermes Agent is bundled with LM Studio and Ollama support.
This push for local, self-improving agents isn’t just for hobbyists tinkering with the bleeding edge. It signals a shift for developers building local tooling, offering a potential pathway to more sophisticated, personalized AI assistants that don’t rely on constant cloud connectivity. It raises a crucial question: are we on the cusp of a truly personal AI, or is this just another layer of complexity that will eventually fold back into cloud-based solutions?
Hermes is an active orchestration layer, not a thin wrapper, enabling persistent, on-device agents instead of task-by-task execution.
This quote from the original announcement is key. It speaks to a desire to break free from the stateless, task-oriented execution that has defined many AI agents thus far. The aspiration is for agents that maintain memory, learn from experience, and evolve their capabilities over time – all without sending your sensitive data off to a remote server. The architecture being pushed by Nous Research and enabled by hardware like NVIDIA’s RTX series and DGX Spark suggests they believe this is achievable, and perhaps, imminent.
But let’s be clear: the promise of self-improvement is the holy grail, and achieving it reliably, particularly in a constrained local environment, is monumentally difficult. The architecture of Hermes, with its focus on contained sub-agents and persistent skill-saving, is a sophisticated attempt to tackle this. The question now isn’t if these agents can be built, but how well they will perform in the messy, unpredictable real world, and whether their ‘learning’ is truly transformative or just a clever form of meta-programming. The hardware acceleration is certainly there to test the hypothesis at speed.



