What if the beastly compute demands of training humanoid robots vanished—poof—into a single workstation?
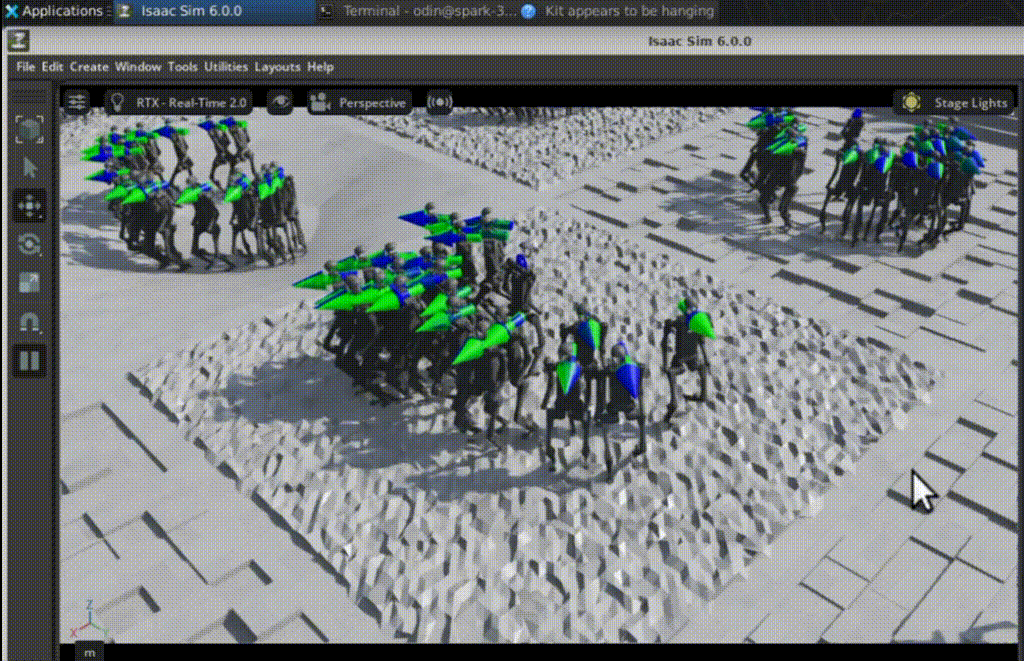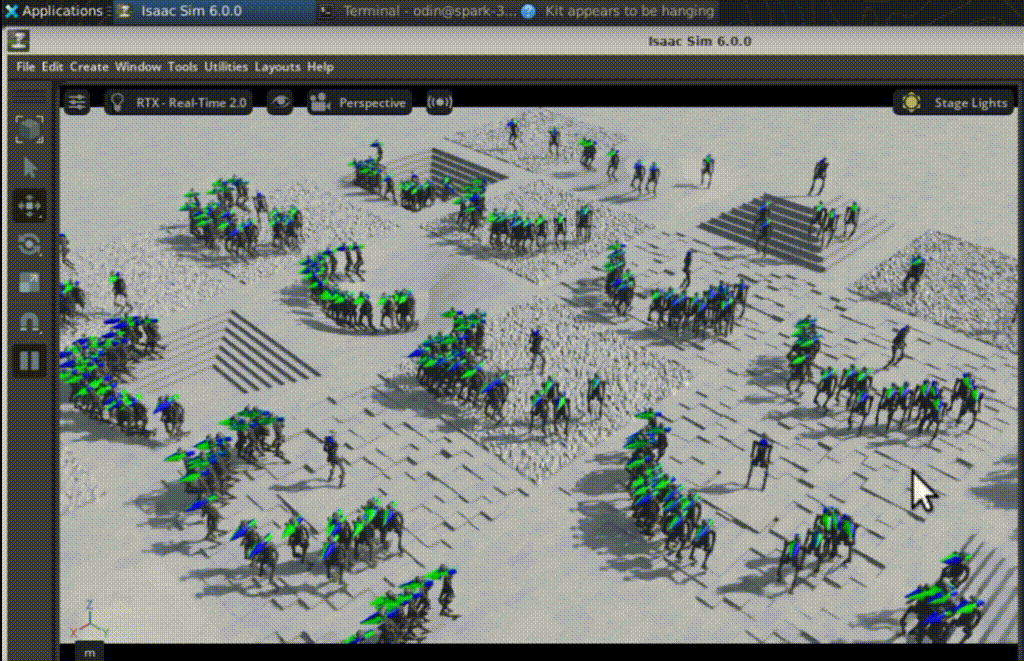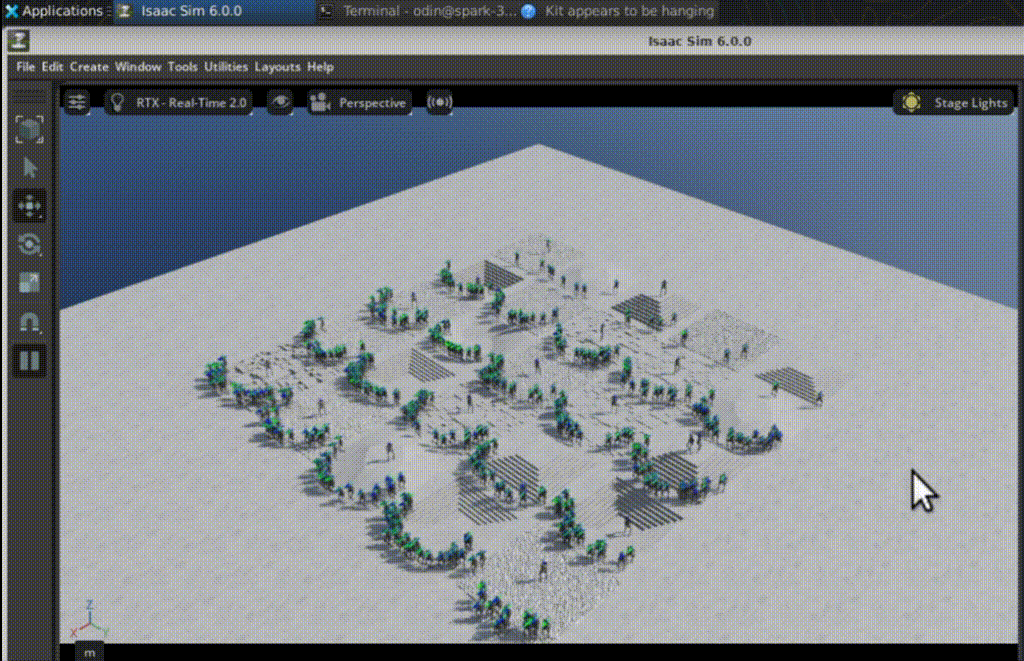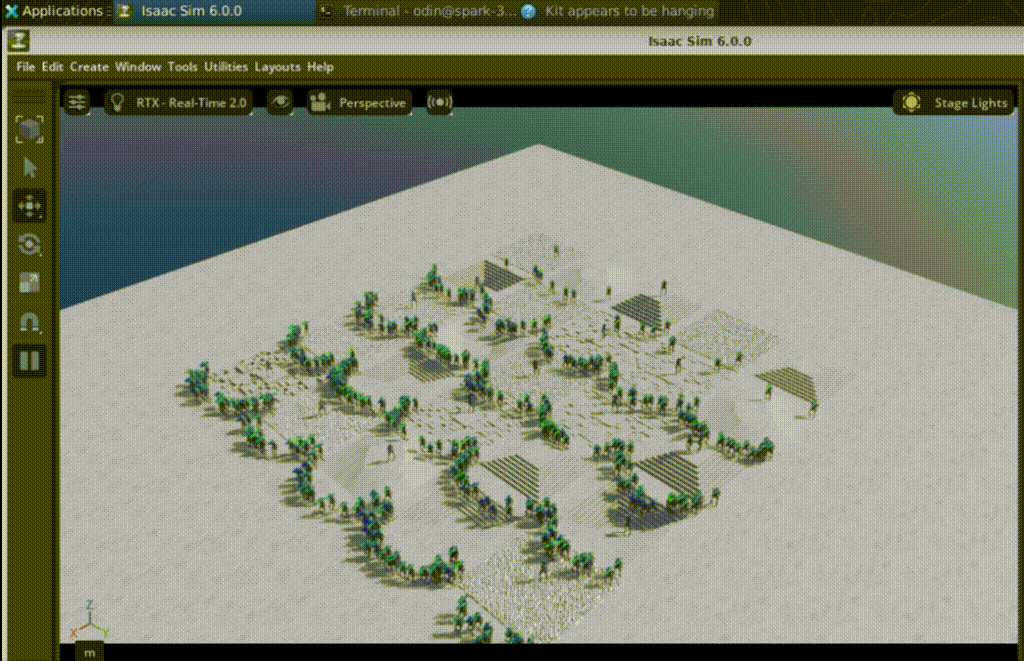
NVIDIA DGX Spark, powered by the Grace-Blackwell Superchip, just made robotics reinforcement learning (RL) feasible on your desk. No sprawling clusters. No x86 crutches. We’re talking a full pipeline: compile Isaac Sim and Isaac Lab natively on Arm, spin up 512 parallel sims, and teach a Unitree H1 to stomp over jagged rocks. It’s not hype; it’s here.
And here’s the kicker—it’s all Arm-native. Build from source on aarch64 Grace CPU. No cross-compilation headaches. The stack? Omniverse RTX for rendering, PhysX for physics, Warp for GPU-accelerated sims. Runs headless, cranks 65,000 steps per second. That’s cluster-level throughput in a box the size of a high-end PC.
Why Arm-Native Robotics RL Feels Like a Cheat Code
Look, robotics sim has been x86’s playground forever. Devs shuttle code between hosts, wrestle emulation, lose days to toolchain mismatches. But DGX Spark? It unifies everything. Grace CPU (72 cores, 480GB LPDDR5X), Blackwell GPU (GB10, 20 petaFLOPS AI), fused via NVLink-C2C at 900GB/s bidirectional.
That interconnect—it’s the secret sauce. Traditional setups ping-pong tensors over PCIe, bottlenecking at 64GB/s. Here? Zero-copy unified memory. Phys sim blasts on GPU across hundreds of envs. PPO updates sip from the same pool on CPU. No transfers. Just raw speed.
RSL-RL handles the algo, PPO tunes the policy for Isaac-Velocity-Rough-H1-v0: 19-joint H1 learns velocity tracking, upright posture, foot clearance over rough terrain. Launch with num_envs=512, and watch metrics climb—mean reward from chaos to steady 3.0+.
At iter 50? Flailing like a drunk toddler. By 1350? Precise steps, balanced gait. Logs match the clips perfectly—reward, episode length, all syncing up.
“This level of performance comes from several architectural advantages: A key enabler behind this throughput is the NVLink-C2C interconnect. It provides a high-bandwidth unified memory space between the Grace CPU and Blackwell GPU.”
NVIDIA’s own words nail it. But they’re underselling—the real shift is Cloud-to-Edge consistency. Experiment on this workstation, scale to DGX pods, deploy to Arm edges like Jetson. No porting wars.
How NVLink-C2C Obliterates the Old Bottlenecks
Picture the old RL loop: GPU sims spit data to CPU over PCIe—latency city. DGX Spark? NVLink-C2C welds them into one memory domain. 1TB coherent space. PhysX on Blackwell chews 512 envs at blistering FPS. Warp kernels (that’s NVIDIA’s sim accelerator) parallelize like mad.
It’s not just fast; it’s efficient. Single node hits what took multi-GPU herds. Power? Under 1kW for the whole rig. Compare to H100 clusters guzzling megawatts for similar tasks.
But wait—why rough terrain? It’s hell for control: uneven footing demands real-time adaptation, torque limits, balance. H1’s 19 DoFs make it a nightmare. Yet PPO converges in hours, not weeks.
This isn’t mere demo-ware. It’s a blueprint. Arm devs, rejoice: full Isaac toolchain—sim, RL, eval—natively yours. No more x86 envy.
Traditional RL? Clusters, siloed stacks, data shuttles. DGX Spark? Workstation, unified, NVLink bliss. Arm workflow from build to deploy.
My take? This echoes the PC revolution—mainframes to desktops democratized compute. Robotics follows. Bold prediction: indie teams will flood garages with custom humanoids by 2026, training solo on Sparks. NVIDIA’s PR spins ‘platform relevance,’ but it’s a startup accelerator in disguise.
Will DGX Spark Spark a Robotics Indie Boom?
Short answer: yes. Cost? Around $30k rumored—steep, but clusters run millions. For labs, VCs, it’s gateway drug. Train locomotion, dexterous hands next? Scale envs to 4096. Plug in real H1 for sim2real transfer.
Skepticism check: is Blackwell overhyped? Nah—GB10’s tensor cores crush RL math. Grace’s Neoverse V2 cores? Beast for policy nets. Early clips show policy maturing predictably—no black-box voodoo.
Critique time: NVIDIA glosses deployment. Sim2real gap persists—domain rand helps, but real-world actuators drift. Still, this workflow bridges it better than ever.
We’ve seen RL fizzle in robotics before—Atari wins didn’t port to legs. Here? Architectural glue makes it stick.
One paragraph wonder: Game on.
The table tells the tale:
Traditional: Multi-node clusters, separate sim/train, heavy PCIe, x86 tools.
DGX Spark: Single Arm box, unified stack, NVLink-C2C, native Arm.
🧬 Related Insights
- Read more: ENIAC at 80: Weavers Who Wove Computing’s First Tales
- Read more: Intel and CrowdStrike Unlock Secure AI on Every PC
Frequently Asked Questions
What is NVIDIA DGX Spark? Compact Grace-Blackwell workstation for AI/robotic workloads—unifies sim and training at desktop scale.
Can you train humanoid robots on a single PC? Yes, DGX Spark runs full Isaac Lab RL pipeline for Unitree H1 on rough terrain, 65k steps/sec with 512 envs.
Why choose Arm for robotics reinforcement learning? Native builds eliminate x86 friction, enables Cloud-to-Edge flow, NVLink boosts throughput sans clusters.




